DeepSeek mHC
解决什么问题(WHY)
Residual Connection
在一个标准的ResNet块中, 输出是输入和一个非线性变换的和:
我们把这个公式从浅层递归展开到深层:
下图对比了标准的ResNet、HC和mHC三种残差连接方式:
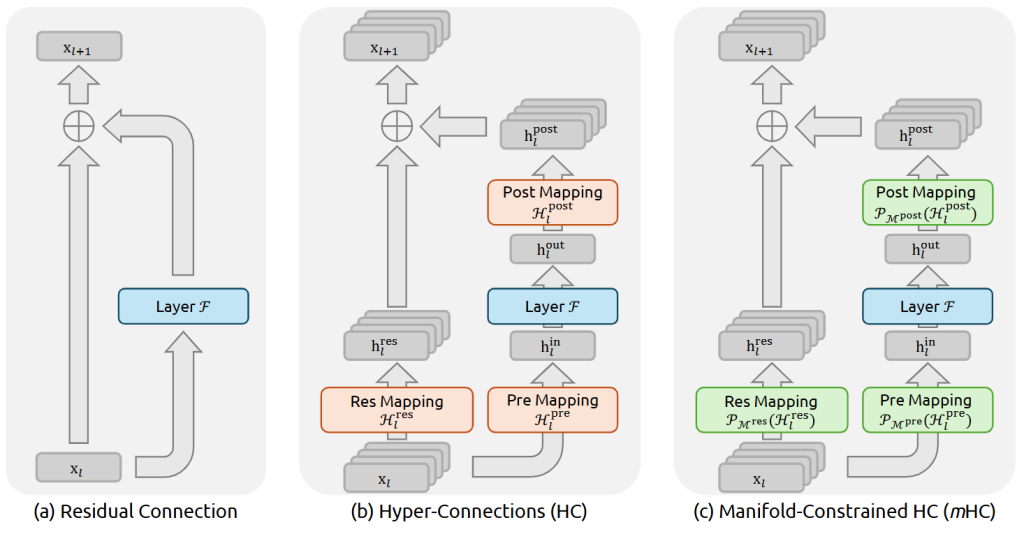
Hyper-Connections
2024 年,字节发了一篇论文叫 Hyper-Connections(HC),入选了 ICLR 2025。他们说,一条残差通道不够用,要把这条路拓宽成四条,还得并行,同时,这四条通道之间,可以互相交换信息,通过一个可学习的矩阵来混合。
HC首先将残差流扩展为n个并行的流,我们用n*C的矩阵来表示:
我们把这个公式从浅层递归展开到深层,先忽略Residual部分:
是一个无约束的 (unconstrained) 可学习矩阵. 这意味着它的元素可以是任意值, 它的性质 (如范数, 行列和) 是完全不可控的。矩阵连乘会产生指数级的放大或缩小效应。
DeepSeek 在 27B 模型上复现了这个问题:训练到 12000 步左右,loss 突然飙升,梯度剧烈震荡,训练崩了。
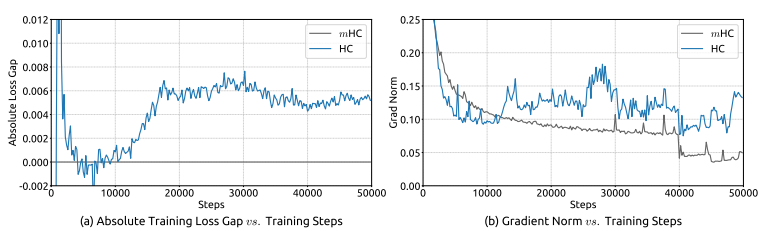
论文里给了一个指标,衡量信号在传递过程中被放大了多少倍
HC 在 27B 模型上,这个数能到多少?3000倍(理想情况下,不应该放大)。
怎么解决的(HOW)
DeepSeek 的思路很直接:问题出在矩阵没有约束,那就加约束。加什么约束?双随机矩阵
这个矩阵有个特点:
- 所有元素非负
- 每一行的和为1
- 每一列的和为1
换句话说,信息经过这个矩阵,可以在四条通道之间重新分配,但总量不变。
信息可以流动,但总量守恒
不管模型有多少层,信号都不会爆炸,也不会消失。用了这个约束之后,27B 模型上的信号放大倍数从 3000 降到了 1.6
为了实现这一点,DeepSeek引入了经典的 Sinkhorn-Knopp 算法。在每次前向传播时,通过几次迭代,将任意的矩阵“拉”回到这个流形上。
Sinkhorn-Knopp算法
Sinkhorn-Knopp算法是一种用于矩阵平衡的迭代算法,主要用于将非负矩阵转换为双随机矩阵(即行和与列和均为1的矩阵)。该算法由Richard Sinkhorn和Paul Knopp在1967年提出,在最优传输、机器学习、图像处理等领域有广泛应用。
算法原理
Sinkhorn-Knopp算法通过交替对矩阵的行和列进行归一化操作来实现矩阵平衡。具体步骤如下:
- 初始化:给定一个非负矩阵A
- 行归一化:对每一行除以该行的和,使行和为1
- 列归一化:对每一列除以该列的和,使列和为1
- 迭代:重复步骤2和3,直到矩阵收敛到双随机矩阵
Sinkhorn-Knopp算法在矩阵A是完全正矩阵(所有元素严格大于0)时具有线性收敛速度。对于非负矩阵,算法可能不收敛,但可以通过添加小的正数到对角线上来保证收敛。
引入的系统开销
理论上的优雅往往伴随着工程上的噩梦。mHC引入了更宽的残差流(n倍宽度)和额外的投影计算,如果直接实现,训练速度会大打折扣。
根据论文第3.2节“系统级开销”(System Overhead)的内容,其主要阐述了Hyper-Connections(HC)架构在实际系统层面带来的显著挑战,这些挑战与计算复杂度(FLOPs)无关,而是源于内存访问(I/O)成本。
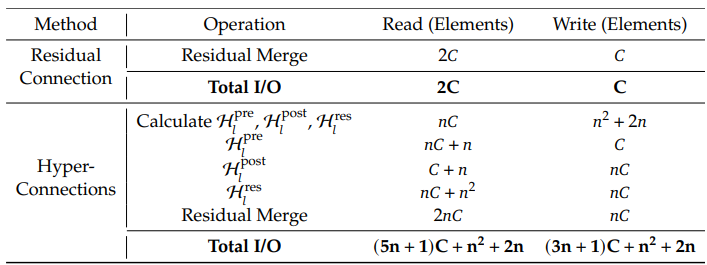
上述表格的IO开销分析如下:
- PreMapping的输入是,所以是,两个矩阵相乘输出是
- PostMapping的输入是PreMapping的输出和所以是,两个矩阵相乘输出是
- ResMapping的输入是,所以是,两个矩阵相乘输出是
- Residual Merge的输入是2个矩阵,两个矩阵相加输出是
针对系统开销,论文在4.3章节给出了Infra相关的优化措施,包括Kernel Fusion、Recomputing、Overlapping Communication in DualPipe,这里不再展开。
启发
信号完整性:传统HC中无约束的残差映射会导致信号在深度传播过程中发生畸变,相当于在信息传输通道中引入了非线性失真。mHC通过双随机矩阵约束,确保每一层的信息变换都是保凸的,相当于维护了信号的“原始保真度”。
分集增益原理:mHC的多流残差设计类似于通信中的分集技术,同一信息通过多个路径传输。双随机矩阵约束确保这些路径之间产生建设性干涉,而不是相互抵消,从而提升整体信噪比。
“微观设计”与“宏观设计”的结合:当前深度学习架构创新主要集中在微观层面(如注意力机制、FFN等),而mHC重新关注宏观拓扑结构设计,通过拓宽残差流宽度和多样化连接模式来提升模型能力,这为架构创新提供了新方向。
可靠性与性能的平衡艺术:通过将超连接投影到双随机矩阵流形上,既保持了HC的性能优势,又恢复了恒等映射的稳定性。这体现了“适当的约束反而能释放更大潜力”的设计哲学。
 (2 votes, average: 5.00 out of 5)
(2 votes, average: 5.00 out of 5)